
Last improved in RY 3.9.4
Assuming that you have exported a backup and reimported it on a new instance, the main step of the reimport is the mappings:
Difficulty of this page
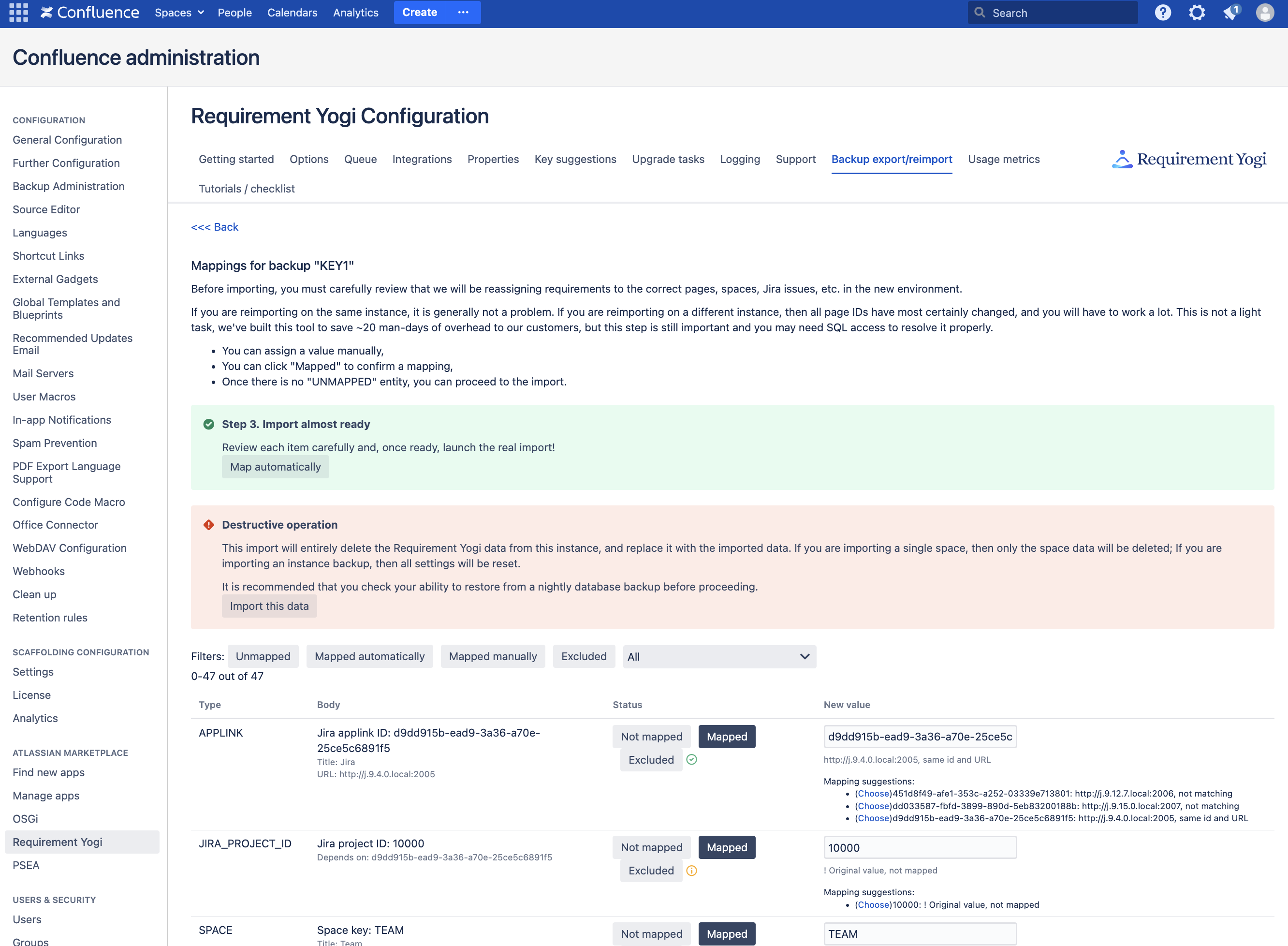
In this page, Requirement Yogi asks you what is the new ID of records on the new instance. If you are reimporting on the same instance, all IDs remain the same. If you are reimporting on a new instance, then all of the Page IDs, User IDs, etc. have changed.
This screen allows you to carefully map the old and new IDs.
It can be very long and very menial to manually check every ID. But it is extremely important to do it well, for the health of the future data. For this purpose, it is smart to access the database in SQL and cross-check the data manually. The data is located in AO_32F7CE_DBBACKUPMAPPING, columns DESTINATIONVALUE and STATUS.
A specific example was provided in Checking that the Jira mappings are correct. The same principle applies to Confluence.
How this page helps you
-
“Map automatically” will try to lookup the values in the new database, and match the records. For example, it will lookup the pages with the same title, and the same version number (only for unmapped and mapped-with-a-yellow-mark records). After this automation, it comes back to this page.
-
“Import this data” will attempt to import the current set of data. Is it marked as a “Destructive operation” because it first deletes the target scope (e.g. it will delete the Jira project if you are importing a Jira project, or the full instance’s Requirement Yogi data if you are importing an instance). After this step, you can come back to the mappings, fix something and reimport.
-
Filters will help you see which records still need to be mapped.
What are the statuses?
-
“Not mapped” means no target value was provided yet. The general action is to click on “Map automatically”.
-
“Excluded” means the record should not be imported. It will also skip the import of all the dependent records. For example, it can be used for a space. It is not advisable to use it for a user, since none of the requirements edited by that user will be imported.
-
“Mapped (green mark)”: The record was entered manually by an administrator, or it was a perfect match during the automatic mapping. It is not possible for an administrator to mark it yellow again.
-
“Mapped (yellow mark)”: The record was mapped automatically, so the correctness is uncertain.
-
During an automatic mapping, values will only be set in “Not mapped” and “Mapped (yellow mark)” statuses. Therefore, if you want the automatic mappings to run again, please set the interesting records as “Not mapped”.
-
Special case: If you don’t want to import a user, you can mark it “Mapped” but leave a blank value.
Example scenario
-
The administrator clicks “Map automatically” as a first step,
-
The administrator then filters by “Mapped automatically”,
-
There are 2 errors. The administrators marks them a read,
-
There are hundreds of objects to map. The administrator filters by space, and clicks on the “Mapped” button to mark them green,
-
Then the administrator filters by pages, searches for the pages in the UI of Confluence, confirms that the ID is correct, and clicks “Mapped” on each record to mark them green,
-
The administrator then clicks “Import this data”, and waits for the task,
-
They notice a small mistake, goes back to the mapping, fixes the mistake, then performs the final import again.
Mapping with SQL
Alternatively, it is possible to set the mappings using SQL.
It becomes particularly useful when page titles contain special characters such as “-”, because the Confluence Search API isn’t able to find such pages. When auto-mappings don’t work, SQL-based mapping very useful.
Mapping page with the same title
Important We’re not expert in Confluence’s core database. The criteria related to the table content (below) were given to us by a customer, but please ensure with an expert that this criterias are reliable, and check yourself that they return unique IDs for every page.
PostGRESQL These SQL queries were written for Postgres. Please adapt for the other DBMS.
-- List the unset mappings, and page suggestions for those mappings
select m."ID", m."SPACEKEY", m."TYPE", m."BACKUPKEY", m."SPACEKEY", m."TITLE",
m."KEY" as OLD_PAGE_ID,
m."STATUS",
m."DESTINATIONVALUE",
m."DESTINATIONHUMANVALUE",
c.CONTENTID, c.TITLE, c.CONTENT_STATUS, c.VERSION
from "AO_32F7CE_DBBACKUPMAPPING" m
left join SPACES s on s.spacekey = m."SPACEKEY"
left join CONTENT c on m."TITLE" = c.TITLE and content_status = 'current' and c.spaceid = s.spaceid
where m."TYPE" = 'PAGE'
and m."BACKUPKEY" = 'YOUR_BACKUP_KEY' -- Update this
;
-- SAVE those mappings
update "AO_32F7CE_DBBACKUPMAPPING" m
set "STATUS" = 'MAPPED_MANUAL',
"DESTINATIONVALUE" = c.CONTENTID,
"DESTINATIONHUMANVALUE" = 'Found using SQL script'
from spaces s
left join content c on content_status = 'current' and c.spaceid = s.spaceid
where
m."TITLE" = c.TITLE
and s.spacekey = m."SPACEKEY"
and m."TYPE" = 'PAGE'
and m."BACKUPKEY" = 'DRIP' -- Update this
and m."STATUS" IS NULL -- Remove this criteria to override existing mappings
;