
📌 In 2.5.1, we've improved the behavior of the queue.
What are the automated actions, when changing a requirement in Confluence?
-
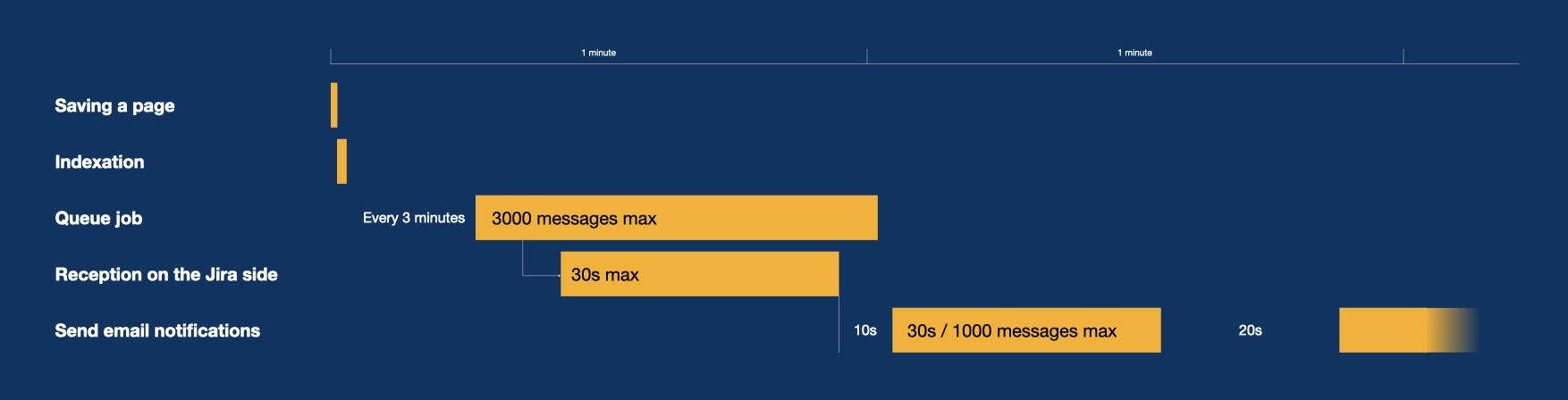
First indexation: A user saves a page. During this action, requirements that exist/don't exist are created/deleted in the database.
-
Second indexation, for the content/properties/dependencies: When the first user views the page, the contents of the requirements are extracted and sent to the server. If those requirements are linked with Jira issues, messages are created in the queue.
-
Queue job in Confluence: Every 3 minutes (precisely at "44 0/3 * ? * *"), the job sends 3000 messages to Jira,
-
Jira receives and treats the messages synchronously, and returns how many have been processed to Confluence. If changes were made to issues, they are saved in a table (AO_42D05A_RYAUDITTRAIL).
-
Notification job in Jira: 10 seconds later, the job "com.playsql.requirementyogijira.notifications" starts and sends email notifications for 30 seconds. If it hasn't finished, it relaunches every 50s.
Can we turn off the queue?
Yes. However, messages will accumulate in the queue. You can:
-
Disable the API in the Confluence administration for Requirement Yogi,
-
Disable the job in the Confluence aministration (Job name: "Requirement Yogi: Send the messages to Jira"),
-
Disable the job in Jira that sends notifications (Job name: "com.playsql.requirementyogijira.notifications"). In this case, all modifications performed by the same user for a given issue are merged, until the next notification job passes (we group notifications for 3 minutes or until the next run of this job).
Failure mode for the queue
When sending from Confluence:
-
We use a timeout of 30s in Jira (or 15s if the queue was sent manually) after which Jira tries to return as fast as possible (it may require a few more seconds). All messages are returned with statuses such as DONE / FAILED (with a message) / NOT_EXECUTED, and with a global error message. This message becomes visible in the Confluence administration.
-
We use the 4x this timeout (=120s) on the Confluence side. If Jira hasn't answered in 120s, we consider all messages as not sent, and we'll try them again in the next batch.
-
Emails are only sent to watchers if the "Send notifications" option was chosen in the Requirement Yogi administration, in Jira. Otherwise, history items are just marked as "Notified", so changes performed later will appear as a separate records.
-
Emails are not sent if the item stayed in the audit trail for more than 1 hour.
-
Locks: We prevent concurrent processing, so even if you have several servers, only 1 queue job, 1 processing on the Jira side, and 1 job of email notifications can be done at the same time.
Queue from Jira to Confluence
-
It is not protected against concurrency yet,
-
Messages are created when an issue is renamed, moved to another project, or when requirements are added/removed.
-
Every 3 minutes, Jira sends 3000 messages of the queue, with 120s timeout (in general, the whole operation takes 3s),
-
Confluence responds and has a timeout at 30s, after which all messages are returned as NOT_EXECUTED. The total may take a few seconds more.
-
No emails are being sent, only dependencies and Jira issue titles cached in Confluence are saved, it is infinitely faster than in Jira.
-
Note that we've measured it could process batches of 50,000 messages sent in 30s every 3 minutes, to enable 1 million messages an hour, but it would require to send requests up to 100MB, and we believe some customers wouldn't handle this. So, unless requested, we'll remain at 3k messages every 3 minutes.
-
It processes 60,000 messages per hour.
How many messages are processed per hour?
-
On an Intel Core i5 3.7GHz and PostgreSQL,
-
We have seen Jira process 700 messages per second on 700 different issues, but it is limited to 3000 messages per batch, every 3 minutes.
-
Then notifications are created in Jira at the rate of 300 per second, but limited to 30s and 1000 per batch. The job runs every 50s (so, 1000 items x 50s).
That means, in the best situation, up to 60,000 queue items would be processed by Jira per hour, and 72,000 emails per hour.
Known remaining bugs
-
All of this was measured with an efficient database. If your database is slower, and even if it is caused by your database having a truely large amount of data, then the queues will process more slowly.
-
If Jira, despite stopping at 30s, doesn't respond within 120s to Confluence, then Confluence is going to send again the exact same batch of messages every 3 minutes.
-
If you have more than 60,000 queue items per hour, there is no way to increase the performance. The queue will increase until your users create fewer items.
-
The queue from Jira to Confluence is not protected yet against concurrency, but it is much faster to send messages.