
Updated: April 2025 - Clarified the message and introduced the comparison tool.
In the release 3.5, we have introduced the back-end indexing. How should an administrator choose between the two indexing engines?
In the release 4.0, we’ve made it mandatory.
What is an “indexing engine”?
It’s the automation which extracts requirements from pages after the user saves them.
How should a customer prepare the transition to the Indexation V2?
-
If you want to check the differences ahead of the migration:
-
Install 4.1 or above, and use the comparator (before or after switching modes),
-
Check whether you are using baselines, or third-party apps in your requirements such as “Scaffolding” (see RY-1160) or “Easy Dropdown Menus”. If so, see the child page for examples.
-
-
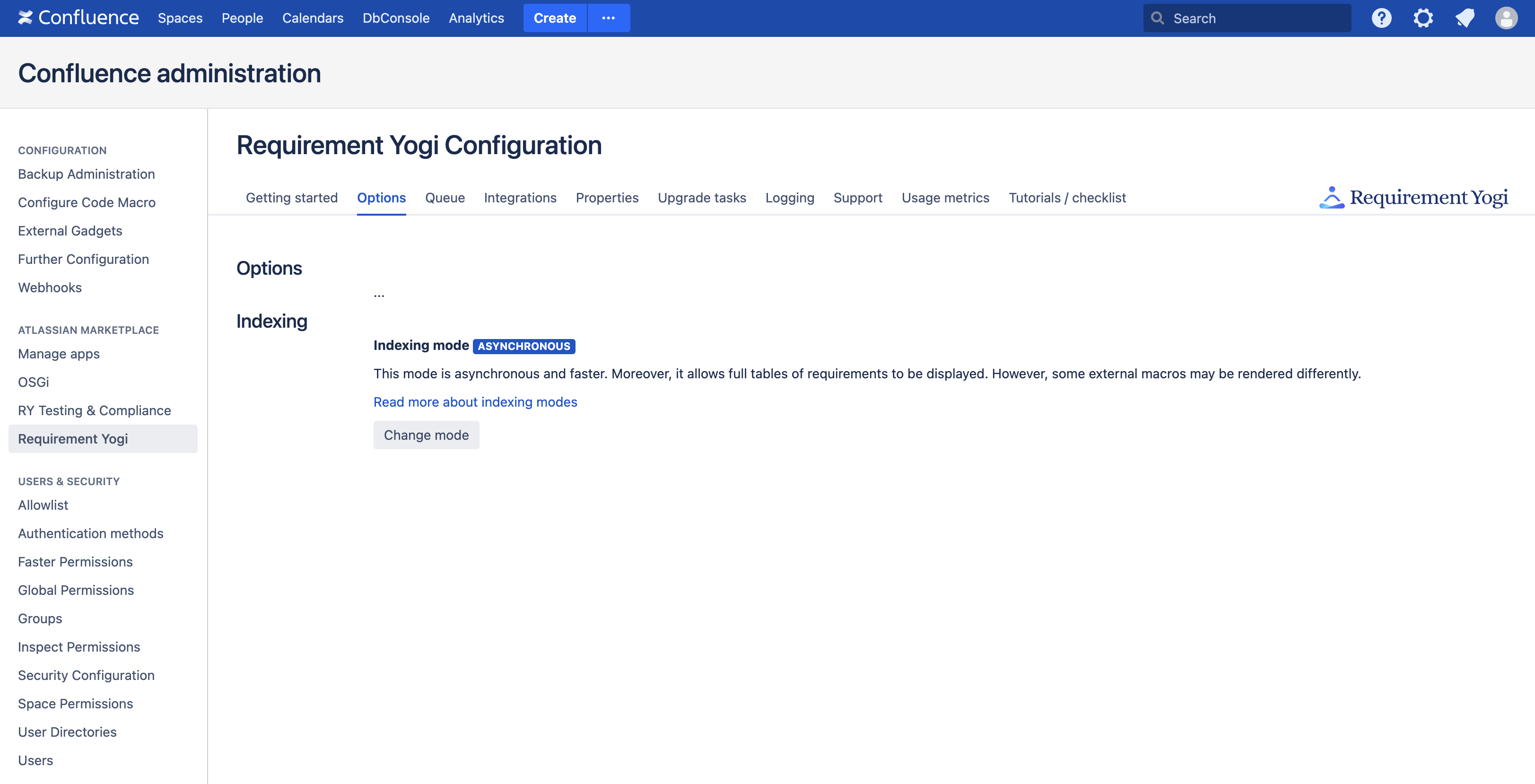
To migrate, switch the setting in the Confluence Administration → Requirement Yogi → Options → Change mode.
-
This mode is applied by default when installing 4.0, but the administrators can revert to Indexing v1.
-
Both coexist in the database, and no “migration” is necessary. We store the indexing version with the requirement text, so your new requirements will be indexed with the new version, while older requirements will remain indexed with the old version. It is ok to have both requirements indexed with the old and new version in the same database.
Why are we doing this change?
-
Shall we start with all the drawbacks of the indexing V1?
-
It was performing the indexation from the webpage, therefore a user needed to attend interactively,
-
It was synchronous, executing while the user was pressing “Save”. So the user was sitting there, waiting for the requirements and dependencies to be saved (25s for 400 requirements, do you start to understand why we’ve pushed to architecture change in 2023?),
-
It was performing twice more database operations due to this mechanism,
-
The server couldn’t throttle the workload because it was synchronous with users. At peak times, it would require n times the RAM for n pages reindexed at the same time, which risked bankrupting the app (We really enjoy the Java Heap Space behaviour when it runs out of memory: Java slows down to a crawl, then crashes).
-
Since it was displayed to the user, we’d only be able to access the front-end rendering of each macro, which didn’t give us access to useful metadata,
-
Reindexation consisted in displaying iframes in which the pages were rendered, so it could reindex each of them,
-
-
Upsides of Indexing v2:
-
It reindexes from the back-end, therefore it can be done at any time, without a user attending the reindexation.
-
Jobs are queued, therefore it smoothens the charge during peak times and spreads out the indexation.
-
Single concurrent job execution ensures our usage of RAM is deterministically limited,
-
We can access the page’s storage format, which gives us reliable data to reindex (We don’t depend on any app’s rendering),
-
We index tables, lists and rich text format without flattening them. That was an unpopular decision that we had taken in Indexing v1, therefore we’ve reverted it in v2.
-
Data Center approval: In our measurements, its performance is more than 2x faster. More importantly, because of throttling queued jobs, we don’t risk causing a Java Heap Space problem during peak times.
-
What are the undersirable changes of Indexing v2?
-
If you have baselines, then the new requirements won’t be easily comparable with the old ones:
-
Note that, even without changing the indexation, every rendering of a page differs slightly, for example if any macro has changed a detail in its implementation, or if macros contain the date,
-
Comparison is still possible, it just requires a human to understand and track the differences,
-
The Comparison tool for indexation can migrate old versions of requirements to the new indexing (optional).
-
-
When using vertical tables, the rest of the requirements of the page were considered children (they had dependencies of type “parent”). This is not the case anymore with Indexing V2.
-
See Comparison between Indexing Engine v1 and v2 if your text is sensitive.
Transition
-
April 2023: The new indexing was introduced in RY 3.5.0, and made it the default for new customers,
-
February 2025: We’ve made it the default in RY 4.0.0, but it is still possible to change.
-
April 2025: We’ve made a comparator in RY 4.1.1, so customers can audit the changes.
The indexing v2 is the only one officially supported for Data Center. The performance of Confluence will be impacted by using the indexing v1.
Did we answer all your questions?
Feel free to ask questions on Requirement Yogi support.