
If you encounter issues during the migration where some pages are not migrated, do not worry, you will always be able to migrate pages at any time in the future.
If you want to know reasons why some pages are not migrated, please read the full documentation. Here’s a recap
-
If there are restrictions on pages, which is very frequent. In case some pages are restricted, then the app’s user can’t view and edit those pages.
-
Requirement Yogi can’t recognise the format of the page because of the legacy editor, or because requirements are embedded into other macros we cannot parse.
-
Confluence rejects the modification, for example if Confluence rate-limited the app because it was performing too many modifications,
💡 The upside of transforming the pages manually, is that this action is performed using the current user’s credentials, instead of the app's credentials.
What types of macros do we transform?
|
Server |
Cloud |
|---|---|
|
|
|
The macros will be replaced by the RY Configuration instead. Find more information here: https://confluence.intranet.requirementyogi.com/wiki/x/LwAHpw . |
|
You’ll have to remove old macros and replace them with the RY Report. Find more information here: Manually migrate RY Report macro . |
|
No replacement for the Baseline macro on the Cloud. |
Migration Dashboard
This option is only for users who have performed a CCMA migration already.
|
1 |
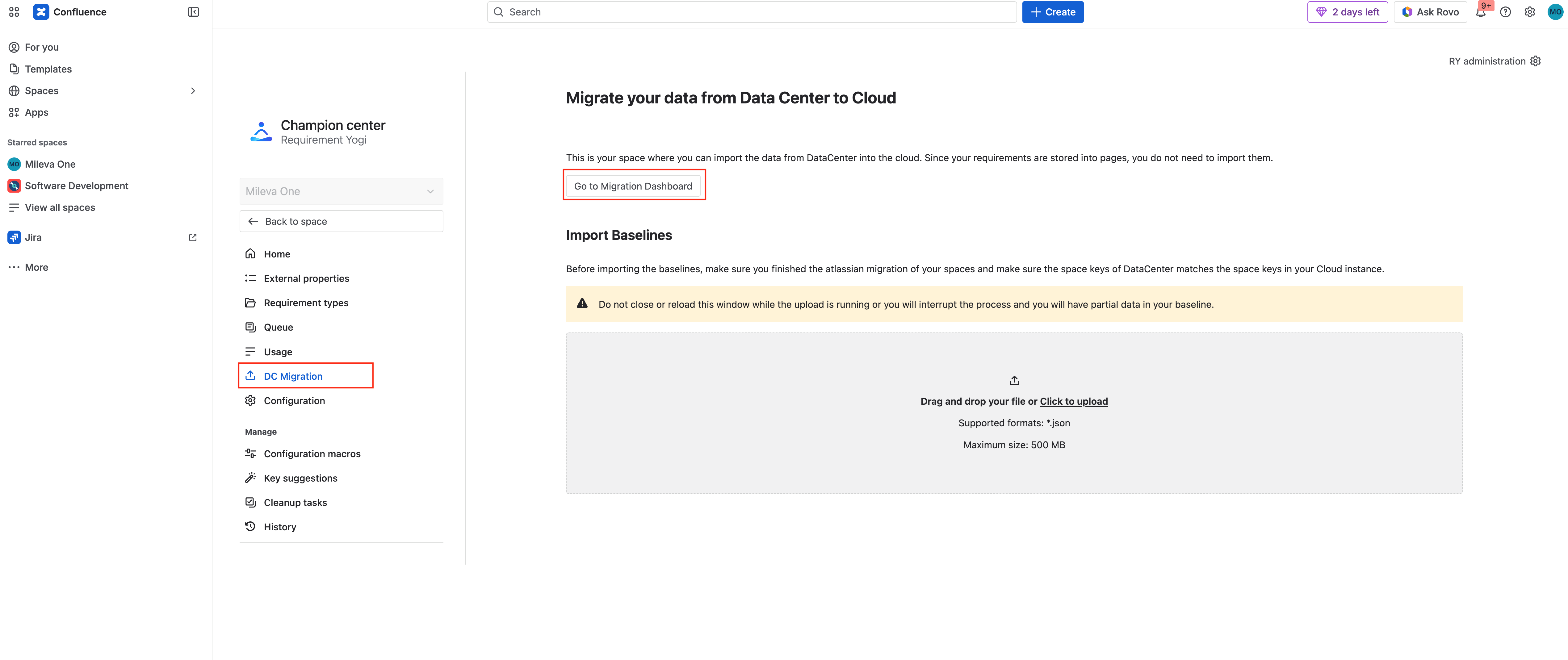
Access the Champion Center > DC Migration > Go to Migration Dashboard. |
|
|
2 |
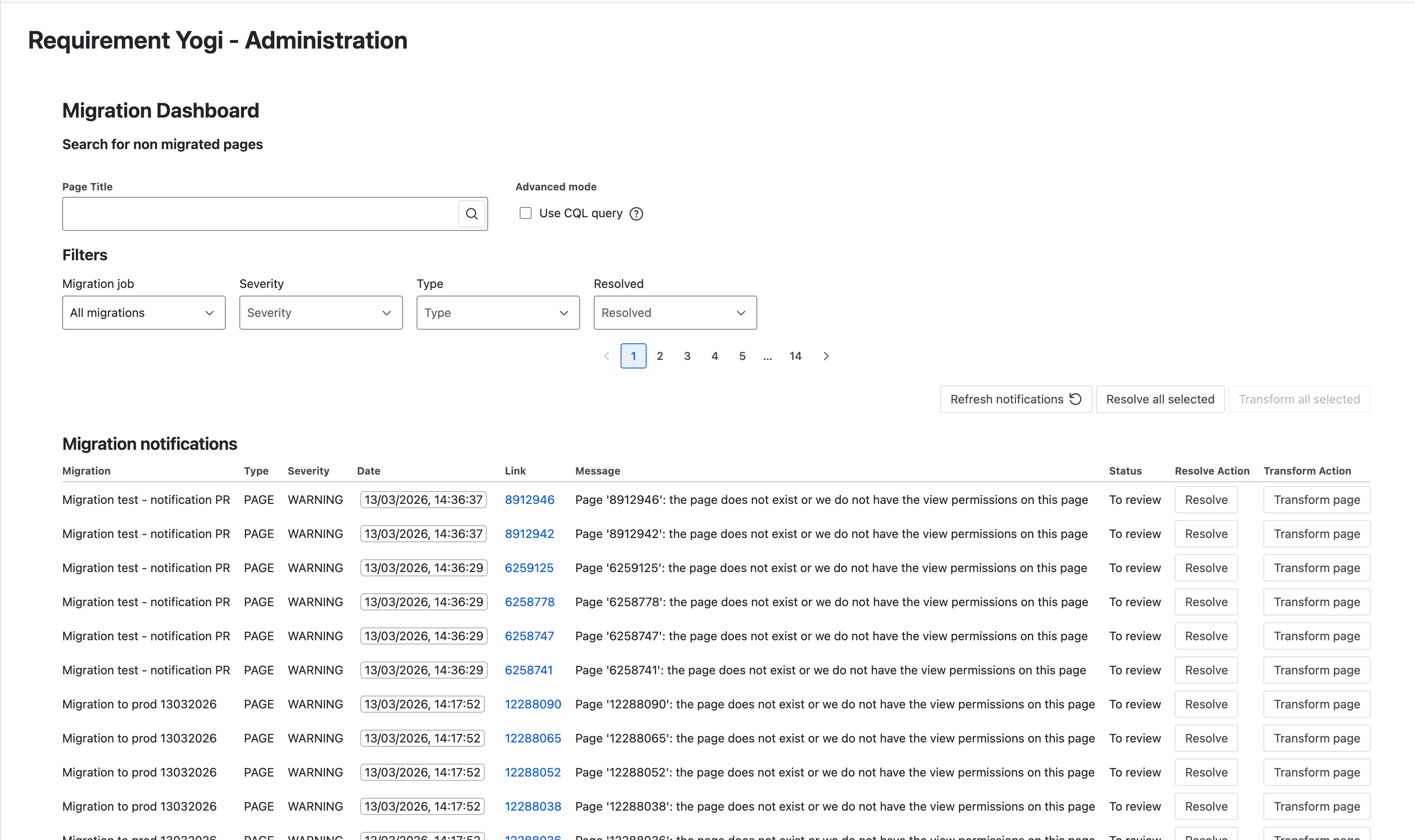
You’ll be able to see all notifications created by your migration in the list.
|
|
|
3 |
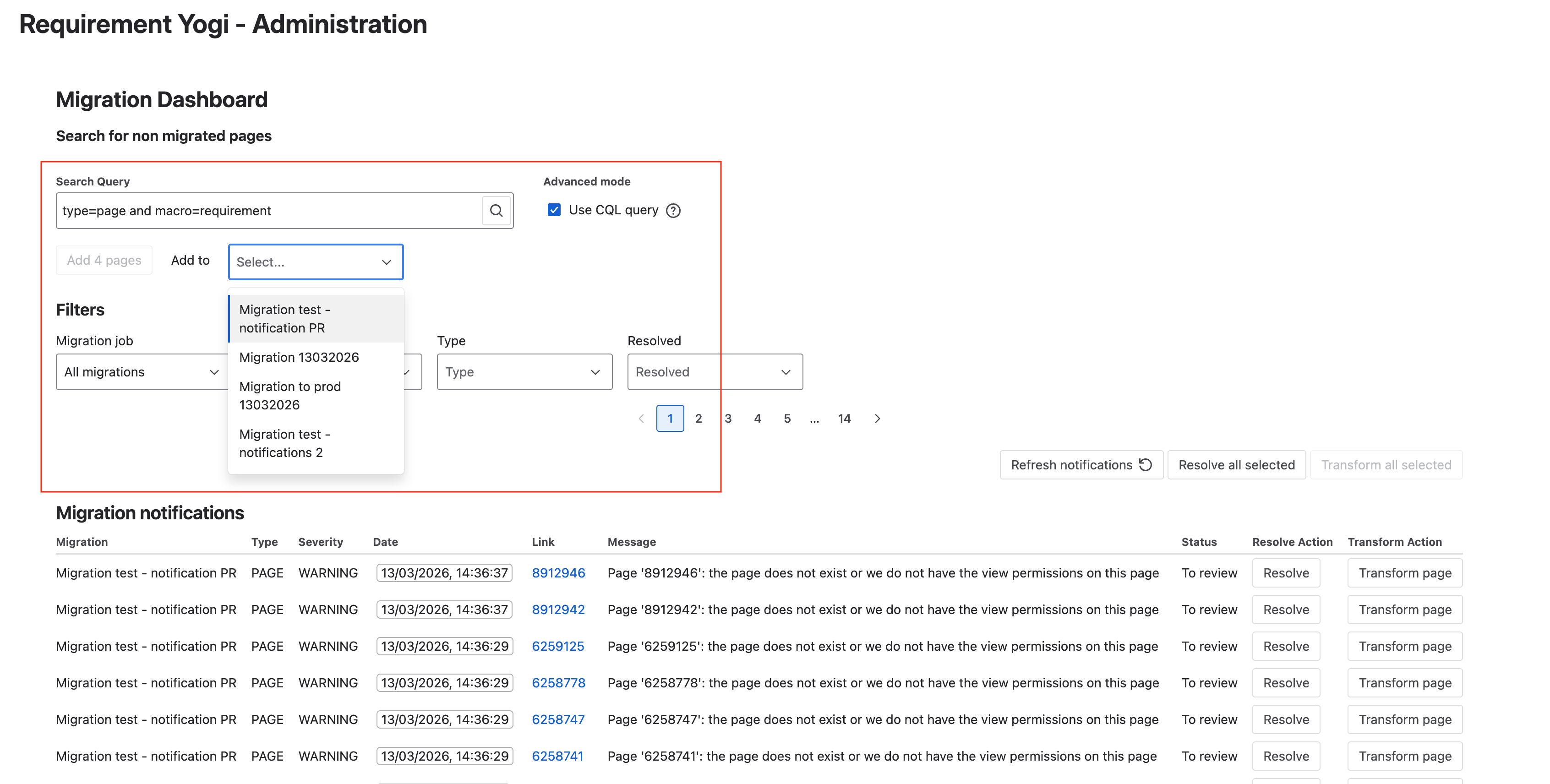
It is possible that some pages were not processed during the migration.Use the search (advanced CQL) and use these queries to find the different items:
Add pages to a known migration. |
|
|
4 |
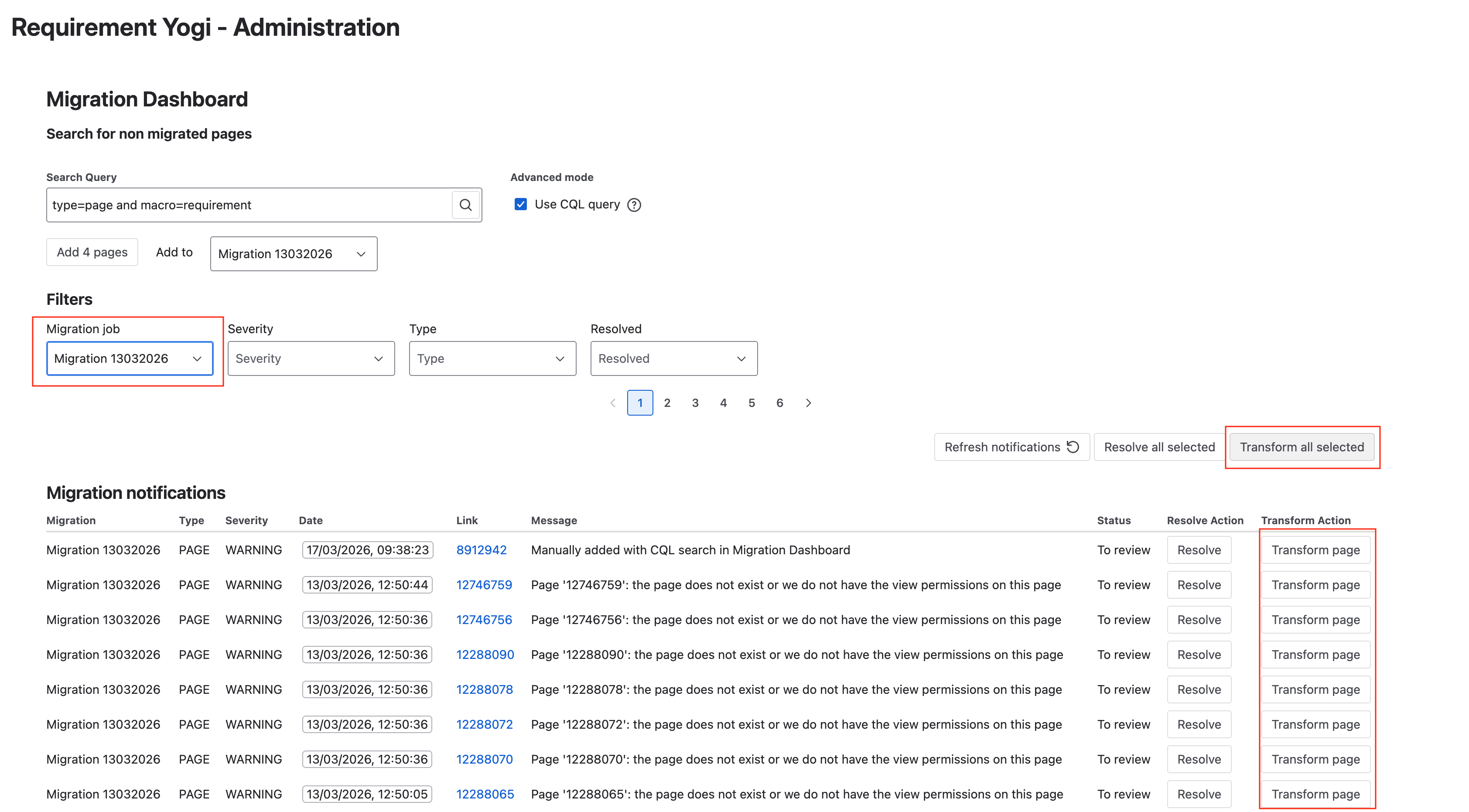
Once all your content is added, you will be able to select a migration, filter with the resolution ‘Pending review’.
|
|
Manual transformation
1. Find Server / Data Center macros
Visually, there is a difference between the Server / Data Center macros, and the Cloud.
|
Server / Data Center |
Cloud |
|---|---|
|
|
|
|
Macros from Server will usually have this message |
This is a functioning macro in Cloud. |
To find non-migrated macros, you can use CQL in our Requirement app:
-
Navigate to Requirements > Transformations tab. Use the search (advanced CQL) and use these queries to migrate the different items:
-
For requirements:
macro=requirement. -
For requirement-properties :
macro="requirement-property". -
For requirement-reports :
macro="requirement-report".
-
You can also use the Rest API to do a search on the whole space using this query: https://your-domain.atlassian.net/wiki/rest/api/content/search?cql=macro=requirement
See more information here: https://developer.atlassian.com/cloud/confluence/advanced-searching-using-cql/
2. Apply the transformation in 1 page
To begin the manual transformation you need to first create and save a transformation on a single page. Then you will be able to apply it on multiple pages, by going into the ‘Transformations’ tab.
|
1 |
Click on the Requirement Yogi Byline (at the top of the page) > Transformation wizard |
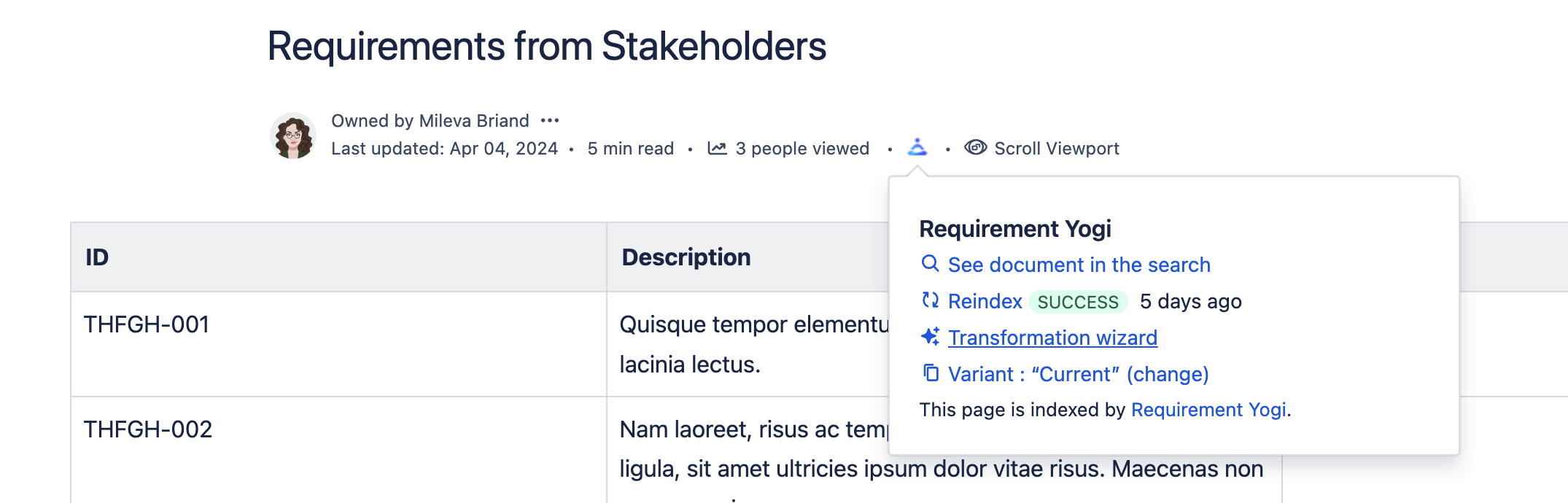
|
|
2 |
Click “Add a transformation” → “Migrate Server macros to Cloud” → Save rule. |
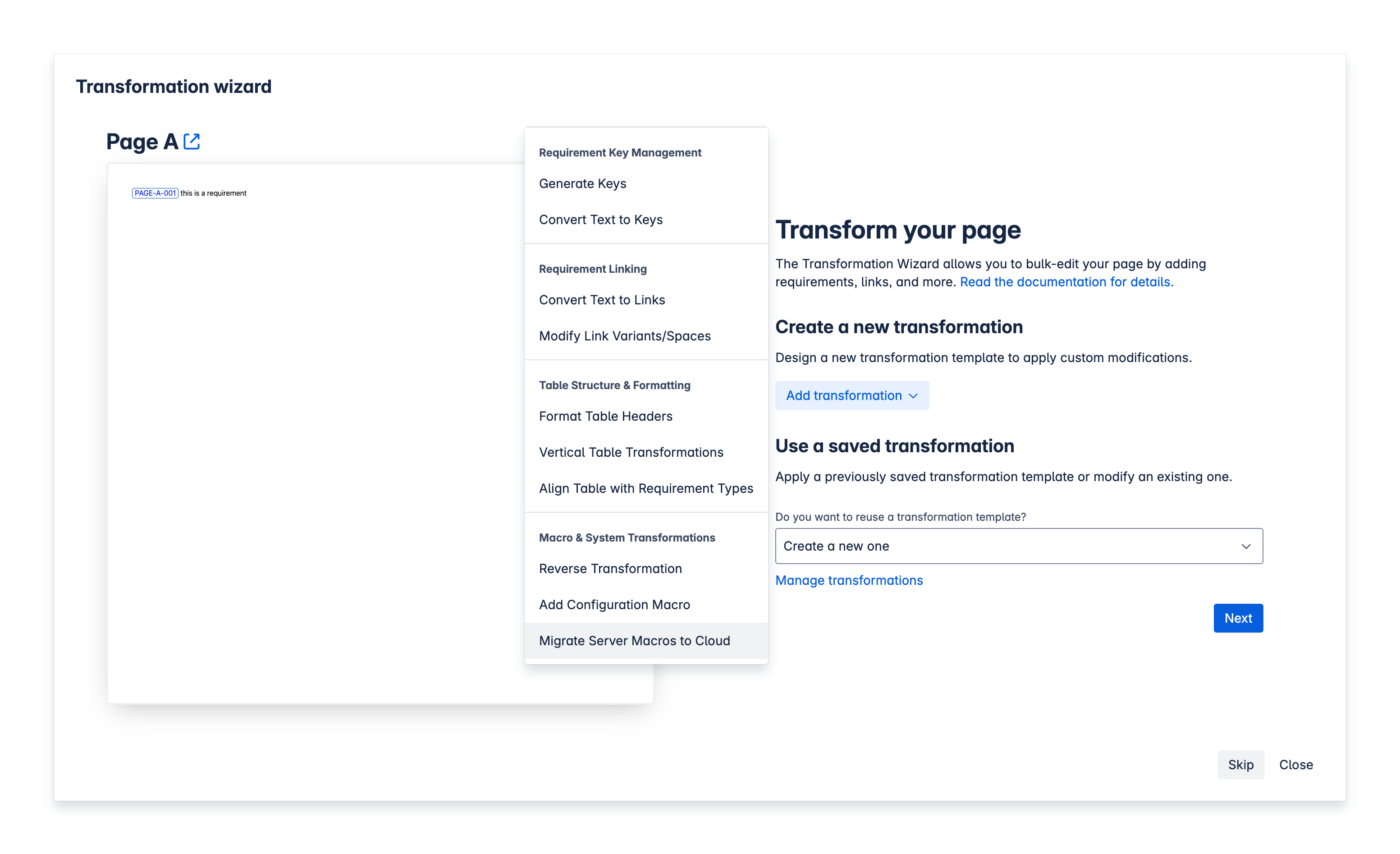
|
|
3 |
Make sure you save this transformation by giving it a name, for example “Migration transformation". Click Transform. |
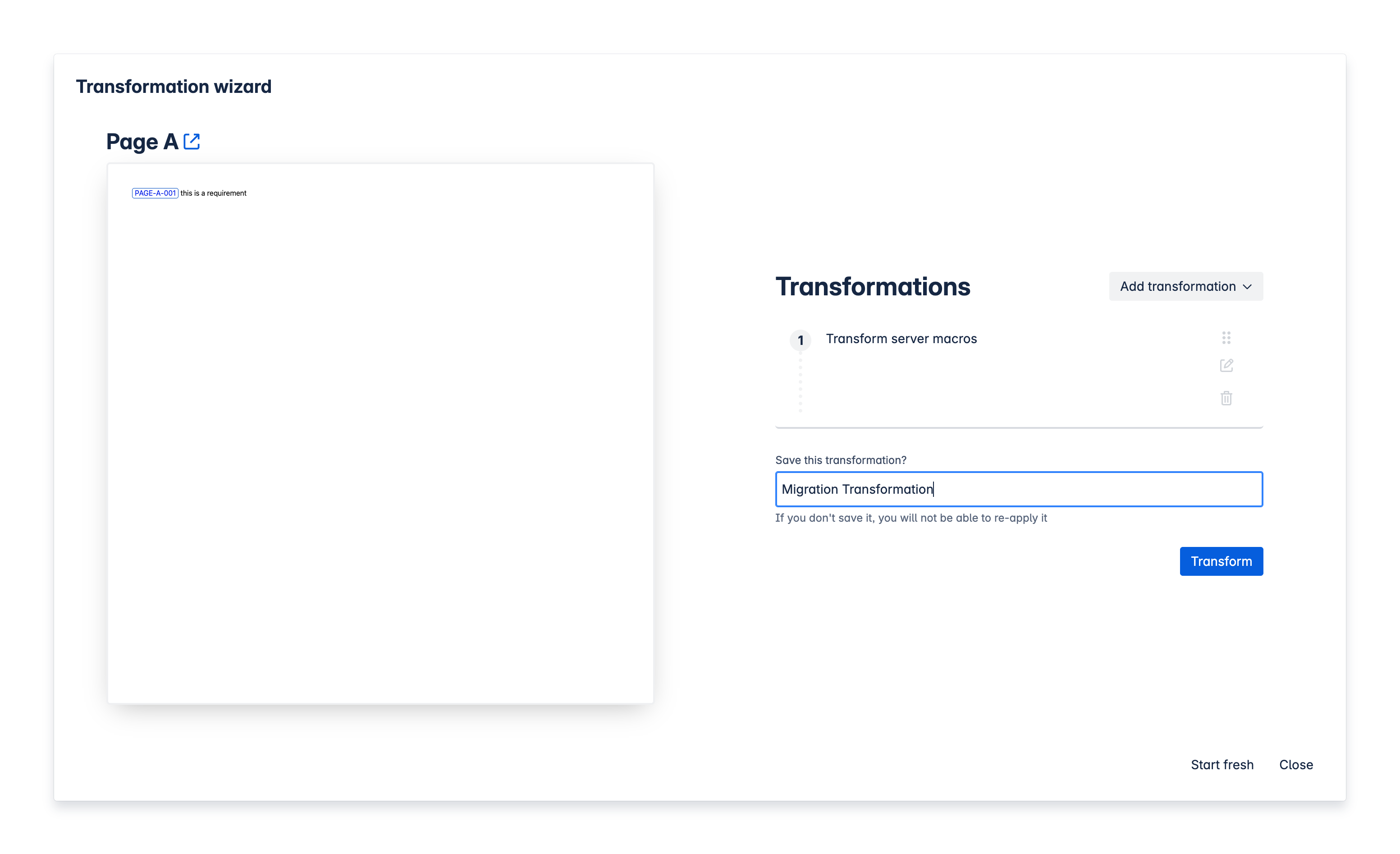
|
3. Transform all non-migrated pages in bulk
|
1 |
Make sure you have already saved the Transformation beforehand with Step 2 above.
|
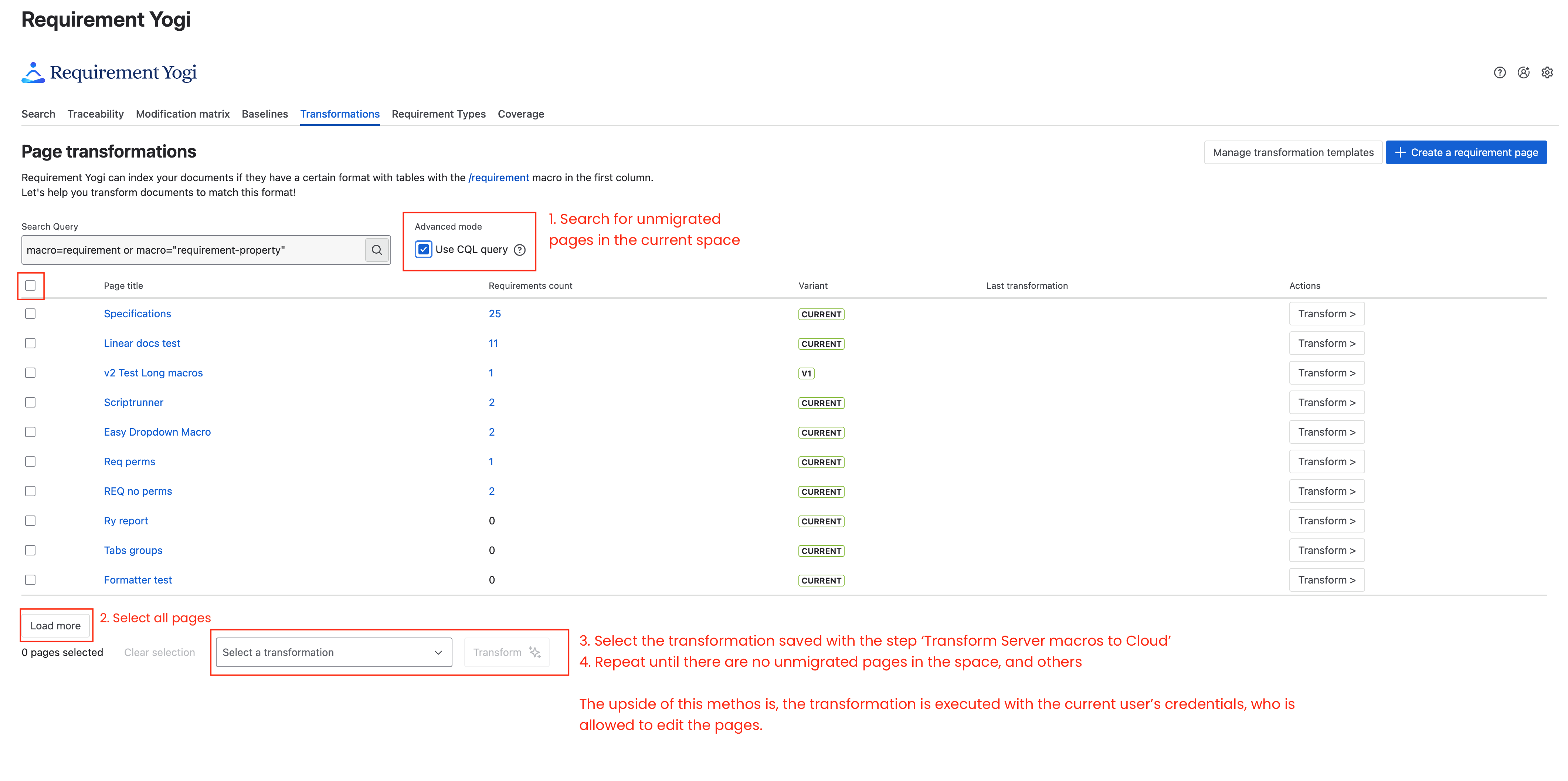
|
|
2 |
Use the search to find non-migrated pages:
|
|
|
3 |
Select all pages and click Transform.
|
Do these steps until there aren’t any more non-migrated pages left in the space. You will have to create this transformation in each space and repeat the steps above on each spaces.
You can perform this step at any point in the future, if you notice that a page wasn’t migrated. Since this search is performed by space, you’ll need to repeat this operation in any space that requires it.
Have any questions ?
Reach out on the support: https://support.requirementyogi.com/