
Please find all frequently asked questions regarding migration prerequisites, steps and troubleshooting in this page.
💡 Please note that the RY for Confluence migration only triggers the transformation of requirement macros from Server to Cloud. If you encounter some issues during your migration, most of the times requirement data will not be lost because they are attached to their Confluence pages. It’s always possible to transform non-migrated requirements later on with a manual transformation.
General questions
What is included in the RY for Confluence migration ?
The migration of our Confluence app includes a transformation of requirement definitions, requirement links and requirement properties macros from Server / Data Center to Cloud format.
At any time, if some requirements are not migrated, you can use a manual transformation to migrate Server macros to Cloud: Transformation - Migrate Server macros to Cloud .
What is not included in the Requirement Yogi migration ?
-
Some RY macros are not migrated and cannot be transformed with the migration / transformation wizard:
-
For reports (
requirement-report,requirement-report-pages), you’ll have to remove old macros and replace them manually with the RY Report. -
requirement-baselinemacros will not get migrated because we do not have an equivalent on the cloud.
-
-
Traceability Matrices and Requirement Types are also not migrated. (But the features still exist so you’ll have to recreate them manually : Traceability matrix Requirement types )
-
Baselines are not migrated within the CCMA, but they can be manually exported and reimported if necessary. Please find the documentation for more information.
What is included in the RY for Jira migration ?
The migration of our Jira app includes requirement links to Jira issues, also applying the relationships.
How to make sure permissions are correct in Confluence Cloud?
On the cloud, if you install an app, an “app user" is automatically created. This user is called Requirement Yogi for Confluence Cloud. Here are the steps to check the user can view and create pages in your spaces:
-
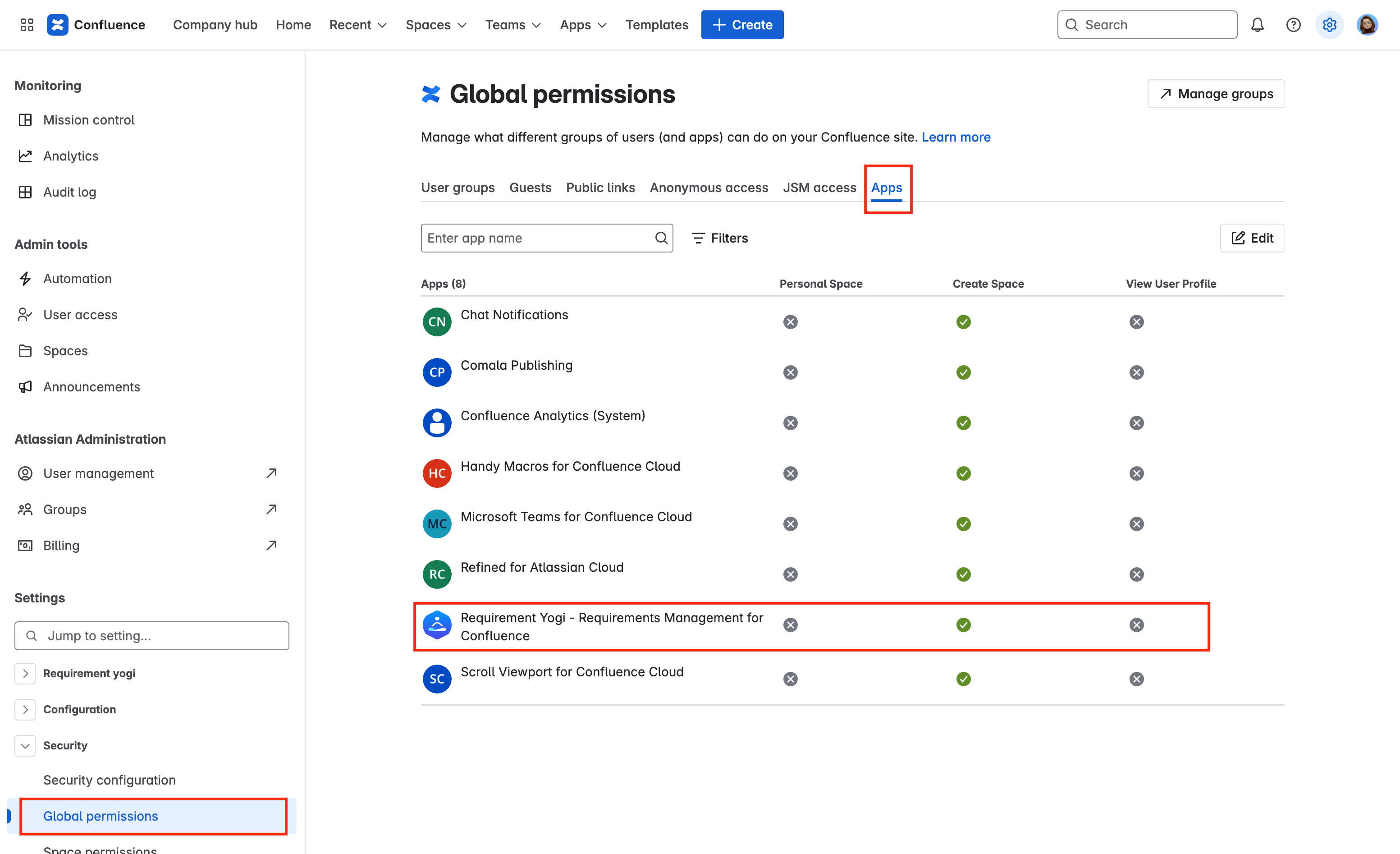
In your Confluence Cloud instance (not Atlassian admin) → Settings → Security → Global Permissions:
-
Requirement Yogi for Confluence Cloudis expected to be in a user group in the User groups tab, -
Requirement Yogi for Confluence Cloudis expected to be listed in the Apps tab, -
If you need help, see the screenshots below.
-
Screenshots for Global Permissions:
.png?cb=3b83de9c03f3f25b78446deea9d6d013)
-
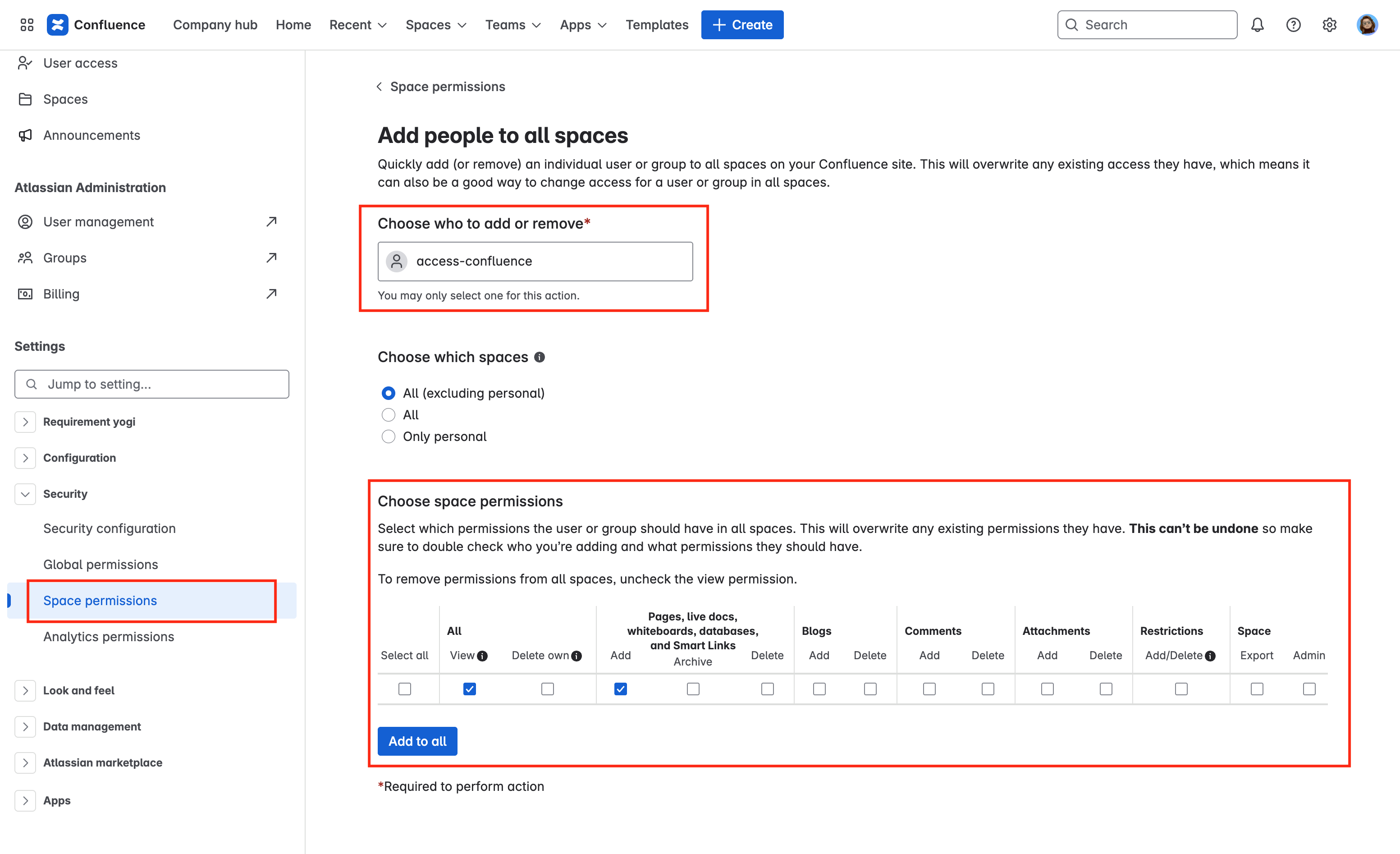
In Confluence Cloud → Settings → Security → Space Permissions:
-
The user group assigned to Requirement Yogi in the previous step is expected to be listed in the Default Space Permissions, with permissions to view and add pages.
-
Personal spaces where you want to use Requirement Yogi may not include the Default space permissions. You can make sure the permissions are correct by clicking on 'Manage access'.
-
If you need help, see the screenshots below.
-
Screenshots for Space permissions:
How do I make sure RY has the correct permissions for restricted pages?
If some pages are restricted, here are the possible solutions:
-
On Server / Data Center, remove all page restrictions by going into the Space Settings > Permissions > Restricted pages.
-
On the Cloud, you can manually include the Requirement Yogi app user for edit permissions. This requires that you edit each page restriction, and it can take some time if you have many.
-
We only need to edit pages during the migration. Once the migration is over, you can remove the pages permission for the app. Requirement Yogi uses the user’s permissions to transform the pages in the Transformation Wizard.
-
How can I find non-migrated content?
Most of the time, migration errors are caused by restricted pages, which prevent us from applying the transformation from Server / Data Center macros to Cloud format.
1. Using CQL
To find pages where the migration has failed navigate to Requirements > Pages tab. To find different types of non migrated macros, you can use different search queries (advanced CQL):
-
For non migrated requirements:
macro=requirement. -
For non migrated requirement-properties :
macro=”requirement-property” -
For non migrated requirement-reports:
macro=”requirement-report"
Remember that you can add type=page to your query to make sure that the results are located in pages and not comments.
Note that it is possible to migrate all those pages manually in the future with the Transformation Wizard.
2. Using the Rest API
You can use the Rest API to do a search on the whole space using this query: https://your-domain.atlassian.net/wiki/rest/api/content/search?cql=type=page AND macro=requirement AND ryc_isMigrated !=true
See more information here: https://developer.atlassian.com/cloud/confluence/advanced-searching-using-cql/
3. Use our migration dashboard and CQL:
We are in the process of implementing a migration-dashboard that will let you use CQL to find non-migrated content over your full instance. For now this tab is hidden but we’ll be more accessible in the future. You can access it by using a direct URL.
-
Go to the Champion Center > DC Migration.
-
Click on the button ‘Migration dashboard’.
This dashboard will also help you to migrate non migrate content with the ‘Transform all’ button: Transformation - Migrate Server macros to Cloud | Migration Dashboard.
How can I count requirement macros on Server and Cloud
You may want to check the requirement macro count from Server and compare it with the Cloud, to make sure everything is fully migrated.
On Server / Data Center
-
Count for whole instance: Check the
macro usageinConfluence Administration, this will give you the count of all requirement yogi macros over the whole instance. -
Count per space: Check the
Requirement Yogi administration>Usage statistics, this will give you the requirement macro count per space, user and over time. This can be useful if you want to know on which spaces you should expect requirements to be created on your Confluence Cloud instance.-
Note that the count for macros
requirementadds up both requirement definition and requirement link macros.
-
-
Count of requirement definitions: In one space with requirements, click on
Requirementsin the sidebar, go to theSearch.
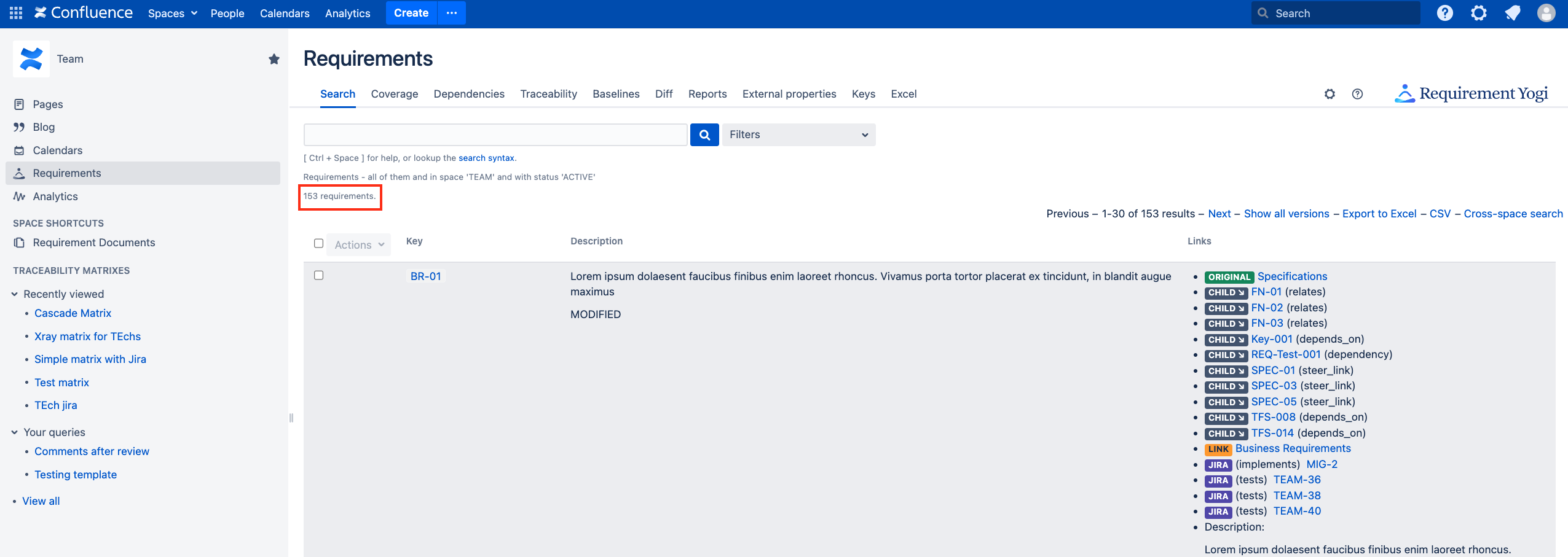
On Cloud
-
Count for whole instance: Check the
Confluence Administration>Data Management>Macro Usage, this will give you the count of all requirement yogi macros over the whole instance. -
Count per space: Check the
Requirement Yogi administration>Usage, this will give you the requirement definition macro count per space.
This is different than Server, the Requirement counts only adds requirement definition macros and not the link macros.
If some requirement counts don’t add up, it’s because the count on the cloud doesn’t count for Server / Data Center macros. In that case, it probably means some of your requirements have failed to be transformed into Cloud macros. See more information to find requirements, and to transform them manually.
Can I perform the Requirement Yogi migration without CCMA and JCMA?
Requirement Yogi for Confluence - CCMA
It is possible to use the transformation wizard to manually migrate server macros to Cloud macros: Transformation - Migrate Server macros to Cloud .
Requirement Yogi for Jira - JCMA
It is not possible to perform the migration manually in bulk in Jira. Once you perform the JCMA and migrate your Jira issues, it is possible to relink existing requirements to Jira but this will require some work.
Information you need to extract from your Server / Data Center instance are: Requirement ids, Issue keys, and relationships.
-
Open a traceability matrix in any space of your Confluence Server instance (with administrator permissions).
-
Use the search query
jira is not nullto only display requirements with Jira links, -
Add a new column: Column heading → cog menu → Jira → All issues,
-
Important: Click “Cross-space search” at the top-right.
-
Export the matrix in Excel if you need to.
Then go to each Jira issue on the Cloud, and create the links manually: Advanced: Bulk link requirements to Jira issues .
Troubleshooting
Why is the migration stuck at 99% or 0% ?
If the migration gets stuck at 99% and eventually fails, you can download the log file in csv to check errors. Most errors could be a Time Out or a permissions error, in any case you’ll be able to migrate your pages by going into the Migration Dashboard.
If your migration is stuck at 0%, it is related to the way Atlassian calculates the migration progress.
-
DC sends notifications to the Cloud with the page IDs to migrate, on the Cloud we check that page and answer back with 'page migrated'.
-
For the percentage to show something other than 0, all the DC notifications need to be sent before CCMA can calculate the percentage between DC notification / Cloud answer.
The status of RY Migration is 'Time out'
Explanations
Atlassian enforces a time out of 25 seconds per page to be migrated. It can happen that because your page is very big or has a lot of macros, you reach this timeout.
Severity
This does not stop the migration from continuing. For example, if page 20 times out, pages 21, 22 etc. will still be processed. In the end, your migration will be ‘Failed’ with a Time Out because at least one page has timed out.
Possible solutions
-
On the DC side, you can edit those pages and split them so they are smaller.
-
Or, you can leave those pages as ‘non migrated’ and use the migration dashboard or manual transformation to migrate them: https://requirementyogi.atlassian.net/wiki/spaces/RY/pages/1907065151/FAQ+Troubleshooting#How-can-I-find-non-migrated-content%3F and Transformation - Migrate Server macros to Cloud
Lots of pages with errors point to old versions of pages
Explanations
When migrating from DC to Cloud, we use a query on DC to recover all the page IDs we need to migrate. This query is filtered on:
-
Whether there are
requirements(orrequirement-properties) in them, -
The status of the page, either in ‘Draft’ or ‘Current’, and we get the latest version.
We’ve seen in some customer migrations that this filter is often not correctly applied and we still try to migrate some pages that are not the latest version (which ends up as an Error).
-
For example, Page A in version 2 will have an id
123, and the same Page A in latest version will have an id234. In the logs of the migration, you may see an error similar to ‘ERROR: Cannot update page with id 123 because status is not {historical}'. If you look for this page id on the Cloud side, you will see it’s version 2 of the page, but if you click on 'View current’, it will be migrated.
Severity
These errors are not critical to the migration as the current version of pages seems to always get migrated in the end. The biggest downside is that it slows down the migration as it adds up page ids that we have to check. (If you migrate 100 pages and you have at least 2 versions for each, it may imply that the migration will be applied on 200 pages instead of 100).
Possible solutions
We’ve done several improvements of these filters and even though we’ve drastically improved the performances and the number of old versions treated, there are still some pages that slip through the filter.
Lots of pages have permission errors
Explanations
When pages are restricted (view), our app user ‘Requirement Yogi for Confluence Cloud’ cannot see which pages have requirements or not, and thus will not be able to transform Server macros into Cloud. This will cause an error, and possibly prevent the migration from going into success.
Severity
If some pages are restricted, it is not a blocking issue for you as a user because it is still possible to transform Server macros into Cloud macros manually. This may take you some time, but this type of error can be acknowledged and fixed later on.
Possible solutions
-
Stop and re-run the migration after fixing permissions issues:
You can stop the migration manually, and fix the permissions manually:
-
Remove page-level restrictions on your Data Center instance, see docs.
-
Make sure the RY for Confluence Cloud app user has permissions to view and edit pages, as seen in this documentation.
Once the permissions are fixed, you can re-run a migration. Please note that it’s always possible to run the Confluence migration without Requirement Yogi, and then perform a separate migration only with the app.
-
Acknowledge the errors manually and migrate macros with the Transformation Wizard
-
When there is an error in the RY Migration notifications, there should be a link to the restricted page. Server macros will appear like ‘Unknown macro: requirement’.
-
Manually click on
Resolveto acknowledge the errors.-
Note this will not actually resolve the issue, it will only allow you to update the status of the migration so you can end it.
-
-
Once the migration is ended, you can process to the manual migration of macros with the transformation wizard per space, or by clicking on the button “Transform pages” in the top right of the migration notification page, view full documentation.
-
💡 The upside of transforming the pages manually, is that this action is performed using the current user’s credentials, instead of the app's credentials.
-
My app doesn’t process any pages
Possible solutions
-
There may be some permissions error.
-
Make sure the RY for Confluence app user has view and edit permissions on pages, see more information.
-
-
If too many pages are in fail, note you can also manually run the transformation wizard to transform server macros to cloud macros, see more information.
Some requirements are missing after the migration
If clicking on a requirement lands on a ‘Requirement does not exist’ page:

Explanations
Most often, it simply means that the page has not yet been indexed.
-
Indexation is triggered by an event on page modifications sent by Atlassian, when editing and updating a page, we should receive a indexation event. Events can take a few minutes, or rarely hours before we receive them.
Otherwise, it is because the indexation of requirement is entirely different between Cloud and Data Center. In some very specific cases, the requirements may then index content differently, or be inexistent. Examples are if your tables have merged cells, double headers and other specific formatting.
Severity
As long as requirement macros are on pages, you will always be able to index them again and we will automatically recover the requirement’s properties, dependencies etc.
Solutions
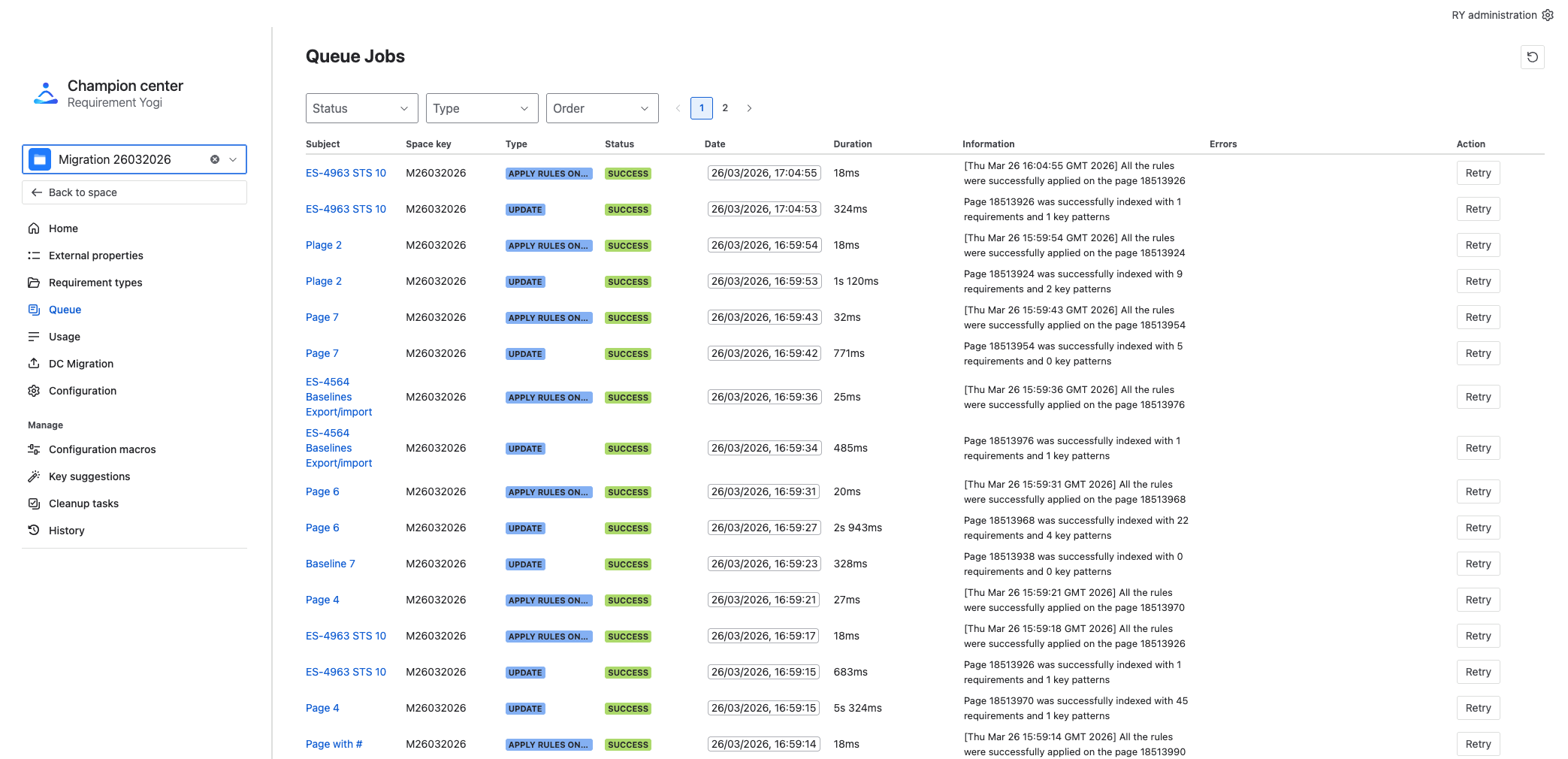
-
Verify the state of the queue in the RY Champion Center > Queue.
-
-
Verify especially jobs with a Failed status, so you can retry them or contact the support team.
-
You can also queue the indexation of a page by clicking on the “Refresh” icon in the Requirement Yogi byline.
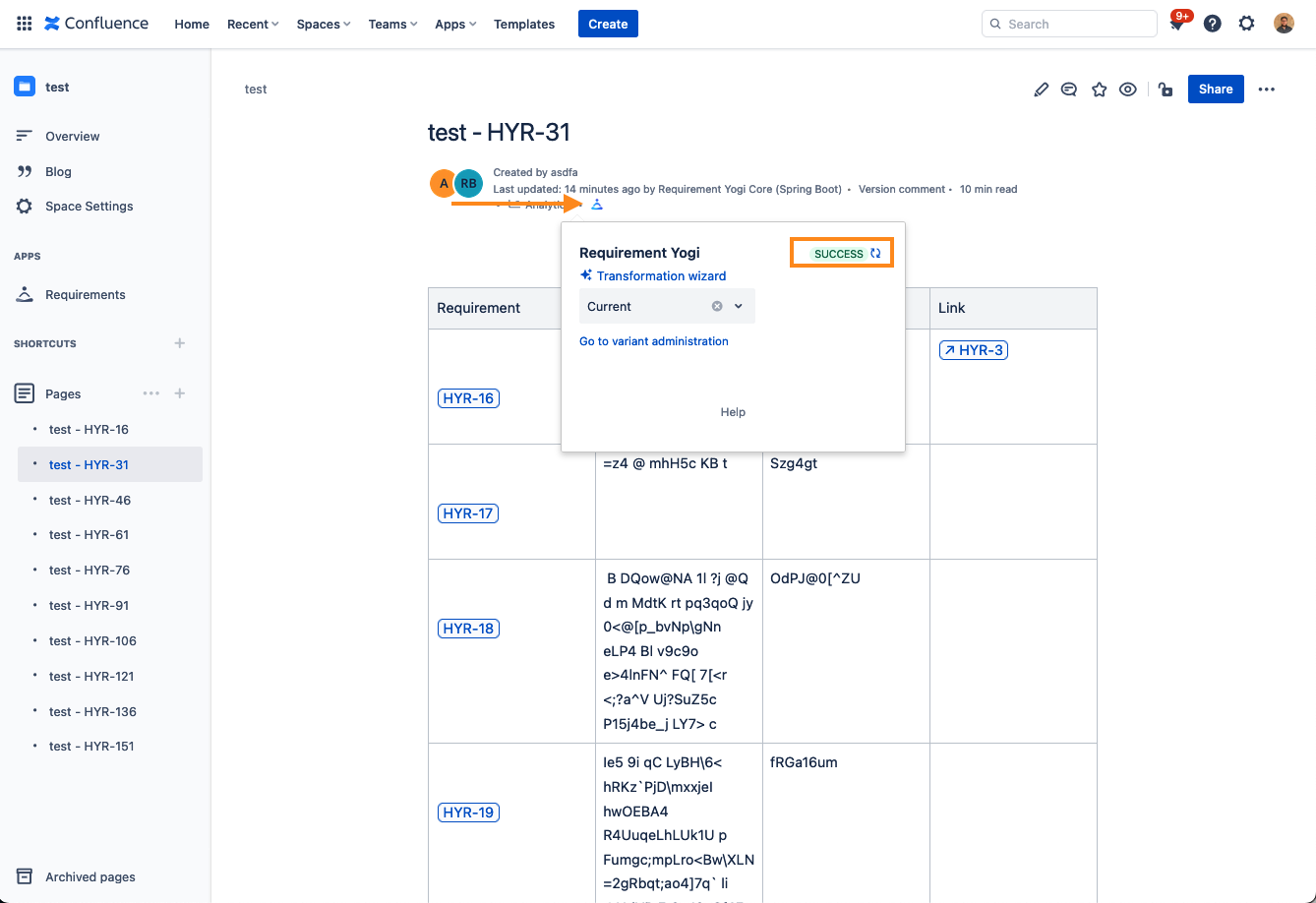
-
If the reindex doesn’t solve the issue, then please reach out on the support and send us the storage format of your Cloud page, and your Data Center page so we can identify the problem. (Storage format can be found by clicking on the three dots in the top right of the page > Advanced details > Storage format).
My requirements are indexed, but there aren’t any properties
Explanations
In Requirement Yogi for Confluence Cloud, the requirement definition macros are expected to be in the 1st column starting at 2nd row with a horizontal table, or 2nd column - 1st row for vertical tables.
In some cases, your table headers may also have a wrong set up.
Severity
This is not a blocking issue, properties are the content of your requirement table, in the Confluence page. As long as you have your Confluence page, your properties will exist for your requirements.
Solutions
-
If your requirements are defined in another column, you can use the configuration macro to map the “requirement” column to the actual column in your table. You can apply this solution on multiple pages using the transformation wizard.
-
You can also edit the settings of the table to set the ‘Header row’ or ‘Header column’. You can apply this solution on multiple pages using the transformation wizard.
The manual transformation does not work
Explanations
There can be some cases in the migration where the editor of the page is still in ‘Legacy’ and we cannot parse the content of the page and perform the transformation.
There can be some cases where your requirement tables are embedded inside another macro, which prevents us from parsing the content of the page and performing the transformation.
Solutions
-
If the manual transformation fails, please try to convert the page to the new (Cloud) editor instead of the legacy editor.
-
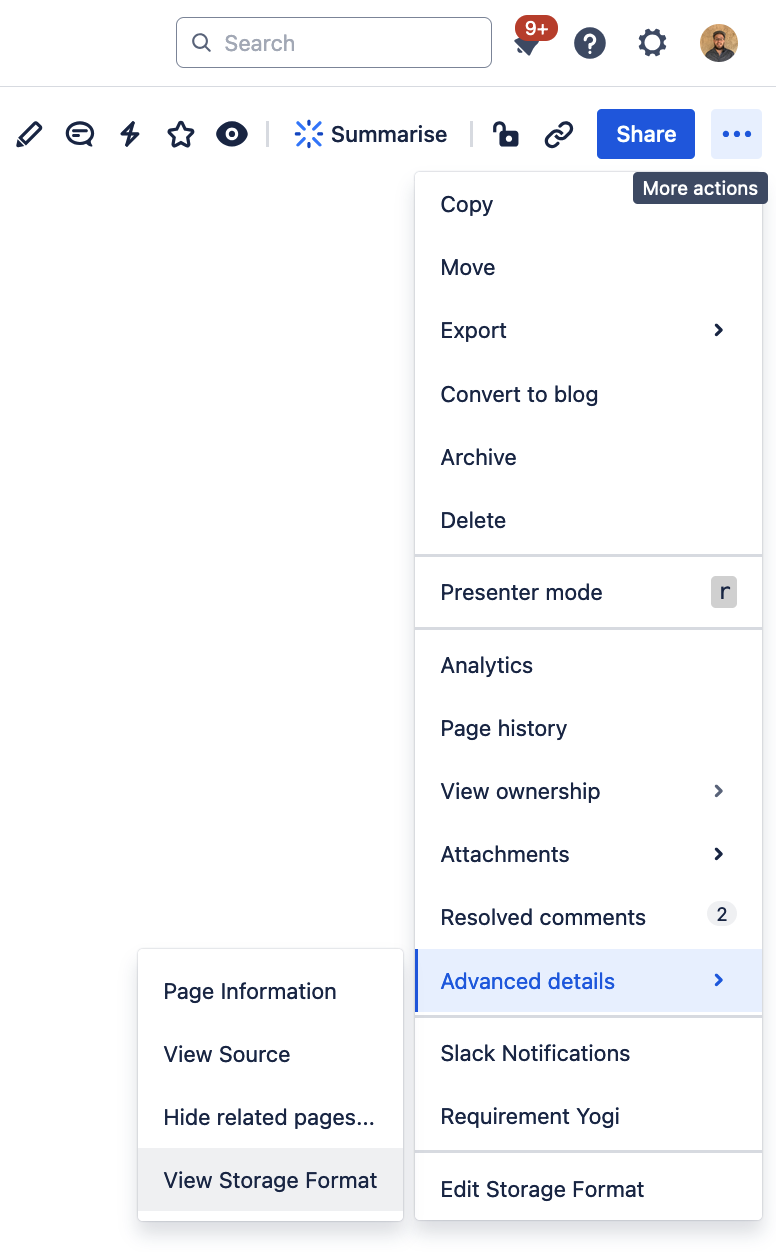
If it still fails after that, please reach out to the support with the storage format of the page:
-
Click on
More actions>Advanced details>View storage format
-
Not finding your answers ?
If you still have questions or would like some reassurance and clarifications, please feel free to reach out. Our team will be happy to help: https://support.requirementyogi.com/.